Blog entry by Stan DeVries.
Data diodes are
network devices which increase security by enforcing one-direction information
flow. Owl Computing Technologies’ data
diodes hide information about the data sources, such as network addresses. Data diodes are in increasing demand in
industrial automation, especially for critical infrastructure such as power
generation, oil & gas production, water and wastewater treatment and
distribution, and other industries. The
term “diode” is derived from electronics, which refers to a component that
allows current to flow in only one direction.
The most common implementation of data diodes is
“read only”, from the industrial automation systems to the other systems, such
as operations management and enterprise systems.

This method is not
intended to establish what has been called an “air gap” cybersecurity defense,
where there is an unreasonable expectation that no incoming data path will
exist. An “air-gap” is when there is no
physical connection between two networks. Information does not flow in any direction. Instead, the data diode method is used as part
of a “defense in depth” cybersecurity defense, such as the NIST 800-82 and IEC
62443 standards. It is applied to
network connections which have greater impact on the integrity of the
industrial automation system.
One-way information
flow frustrates the use of industrial protocols which use the reverse direction
to assure that the data was successfully received, and subsequently triggers
failsafe and recovery mechanisms when information flow is interrupted. A data diode can pass files of any format and
streaming data such as videos and an effective file transfer, vendor neutral approach,
in industrial automation is to use the CSV file format. The acronym CSV stands for comma-separated
values, and there are many tools available that quickly format these files on
the industrial automation system side of the data diode, and then “parse” or
extract data on the other side of the data diode.
There are 2 architectures
which are feasible with data diodes, as shown in the diagrams below.
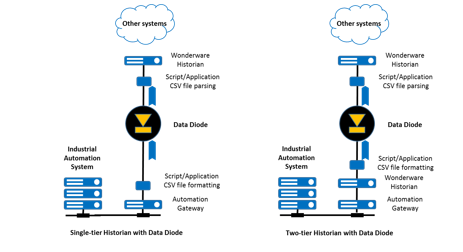
The single-tier
historian architecture uses the industrial automation system’s gateway, which
is typically connected to batch management, operations management and advanced
process control applications. This
gateway is sometimes called a “server”, and it is often an accessory to a
process historian. A small software
application is added which either subscribes to or polls information from the
gateway, and this application periodically formats the files and sends them to
the data diode. Another small
application receives the files, “parses” the data, and writes the data into the
historian.
The Wonderware Historian
version 2014 R2 and later versions can efficiently receive constant streams of bulk
information, and then correctly insert this information, while continuing to
perform the other historian functions.
This function is called fast load.
For L2-L3
integration, the two-tier historian architecture also uses the industrial
automation system’s gateway. The lower
tier historian often uses popular protocols such as OPC. This historian is used for data processing
within the critical infrastructure zone, and it is often configured to produce
basic statistics on some of the data (totals, counts, averages etc.) A small software application is added which
either subscribes to or polls information from the lower tier historian, and
this application periodically formats the files and sends them to the data
diode. Another small application
receives the files, “parses” the data, and writes the data into the upper tier
historian.
The Wonderware Historian has been tested with a
market-leading data diode product from Owl Computing Industries, called OPDS,
or Owl Perimeter Defense System. It uses
a data diode to transfer files, TCP data packets, and UDP data packets from one
network (the source network 1) to a second, separate network (the destination
network 2) in one direction (from source to destination), without transferring
information about the data sources. The
OPDS is composed of two Linux servers running a hardened CentOS 6.4 operating
system. In the diagram below, the left
Linux server (Linux Blue / L1) is the sending server, which sends data from the
secure, source network (N1) to the at-risk, destination network (N2). The right
Linux server (Linux Red / L2) is the receiving server, which receives data from
Linux Blue (L1).

The electronics inside OPDS are intentionally
physically separated, color-coded, and manufactured so that it is impossible to
modify either the sending or the receiving subassemblies to become
bi-directional. In addition, the two
subassemblies communicate through a rear optic fiber cable assembly which makes
it easy for inspectors to disconnect to verify its functionality. The Linux Blue (L1) server does not need to
be configured, as it accepts connections from any IP address. The Linux Red
(L2) server, however, must be configured to pass files onto the Windows Red
(W2) machine. This procedure is
discussed in section 8.2.2.6 of the OPDS-MP
Family Version 1.3.0.0 Software Installation Guide. The 2 approaches can be combined across
multiple sites, as shown in the diagram below.
Portions of the data available in the industrial automation systems are
replicated in the upper tier historian.